
There’s ever more Matlab functions to be discovered, as I mentioned lately. I took the time and finished reading the „Neural Network Toolbox 5 User’s Guide“. At the moment I can’t use most of the divide* functions as I’m using an older Matlab release. Something that works is postreg which can be used to perform a regression analysis between the network response and the corresponding targets. Since I assume that it might be useful to study the impact of two network parameters on the model, I decided to vary the learning rate and the hidden layer size of the neural network. This makes for nice 3D plots:

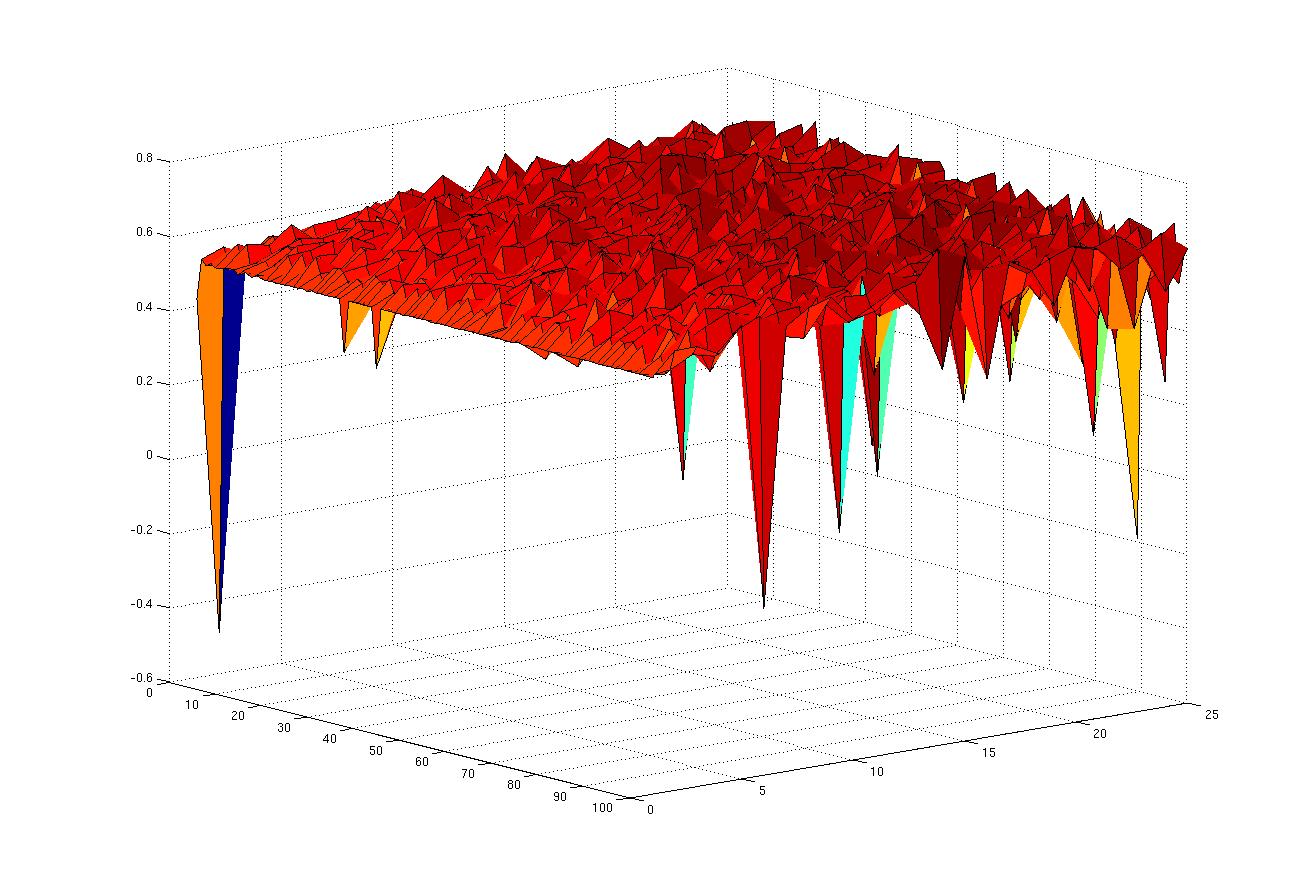

Both show the value of the correlation coefficient between the simulated output and the actual target. The first one does this for the training set, whereas the second one does this for the validation data (that was not included in training). The third plot combines both, although it’s hard to find an appropriate viewing angle. The hidden layer size was varied from 1 to 25, and the min_grad parameter was varied from 0.1/1 to 0.1/100 (hence the 1-100 scale).
The network works as expected:
- with more available weights (growing hidden layer), the approximation gets better
- with a smaller gradient (i.e. longer learning time) the approximation gets better
The script can be found here: agricult_08.m.