The latest experiments with the sports science data always turned out outrageously high errors which most of the time missed the scale of the original attribute by orders of magnitude. After conducting some experiments which returned negative conclusions like:
- the error is too high, therefore the network cannot be trained on these data or
- there is some tendency to overfitting when the network size and the learning rate increase, but the error is way too large anyway,
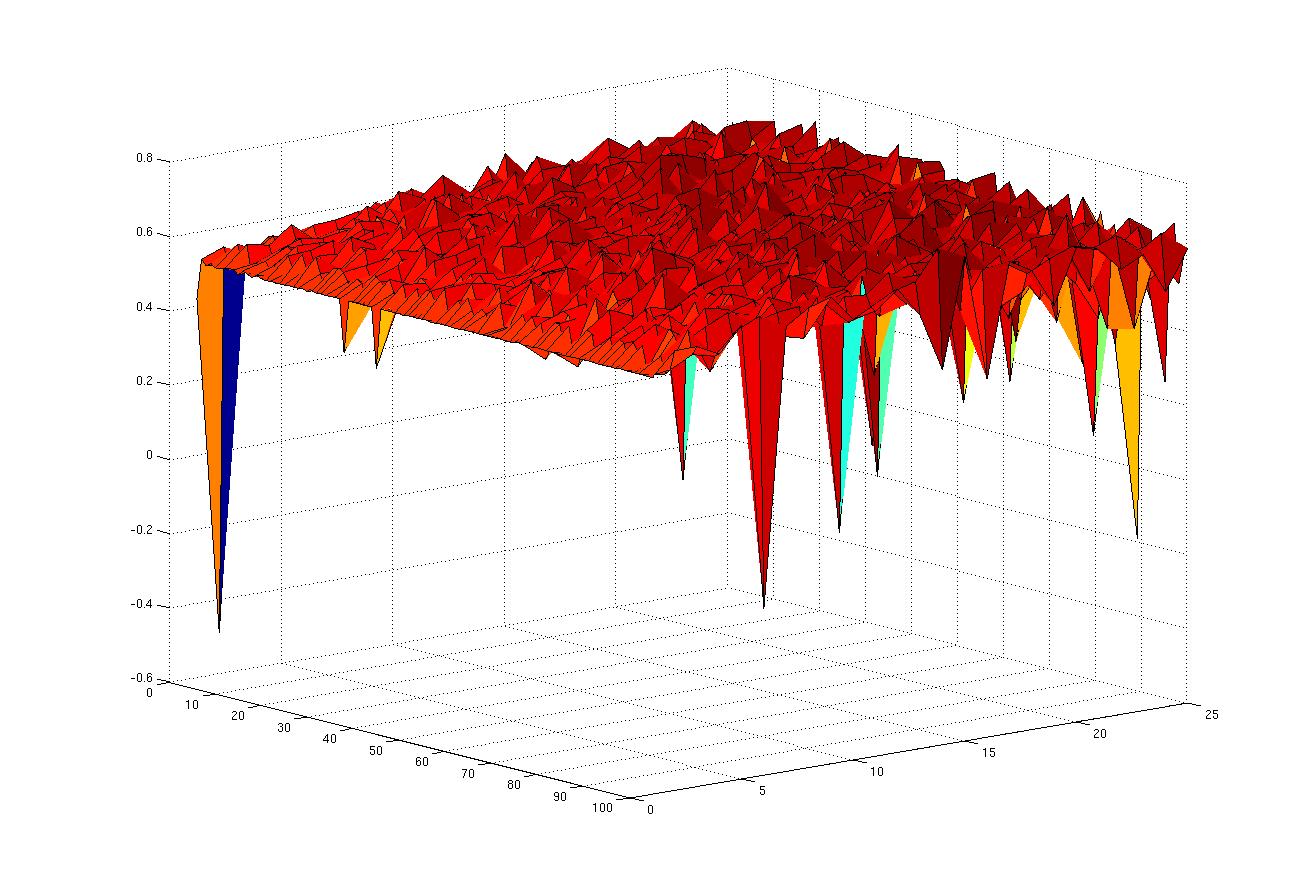
I presented the examples to the sports science people which were also quite surprised about the error’s order of magnitude. When returning back to my office, I had the sudden idea what I had actually shown in the graphs — after taking the sqrt of the mse I ended up with what I had actually wanted to show in the plots: the absolute error, i.e. the absolute of the difference between the predicted result from the network and the actual result. It’s somewhat embarrassing, anyway, but at least I know the cause of the high-error issue.
For the plot below I also got some advice from the sports science people to take out some redundant data (four columns out of 24 are more or less sums of three others each). Now the error is in a region that is more reasonable when a min/max of 841/1004 are expected for the target attribute. The plot shows error vs. the size of the first and second hidden layer of the feed-forward network, respectively.